リンク
Meaningful availability | the morning paper
抜粋・メモ
- 可用性のメトリクスはmeaningfulでpropotionalでactionableで有るべきだが世間ではそうなっていない
- meaningful: ユーザエクスペリエンスを捉えている
- proportional: ユーザ視点での可用性の変化に即している
- actionable: システム管理者に,なぜ可用性が低下しているかを示すことができる
- より具体的な課題
- 時間ベースのメトリクス(MTTF / (MTTF + MTTR)とか)はダウンタイムが全ユーザに等しくかかるという暗黙の前提がある(中央集権的なシステムなので) → 分散システムになると,一部が落ちたとき,一部のユーザが影響を受けるが,このときのダウンタイムが何を指すかは明確になっていない
- 処理できたリクエスト数を用いるカウントベースのメトリクスもある → よく使うユーザに偏ったり,障害が出ているときはそもそもリクエストが減ったり,どれくらいの期間システムが使えないかという観点を取りこぼしていたりと問題あり
- GoogleがG Suiteで使っているメトリクスがwindowed user-uptimeの提案
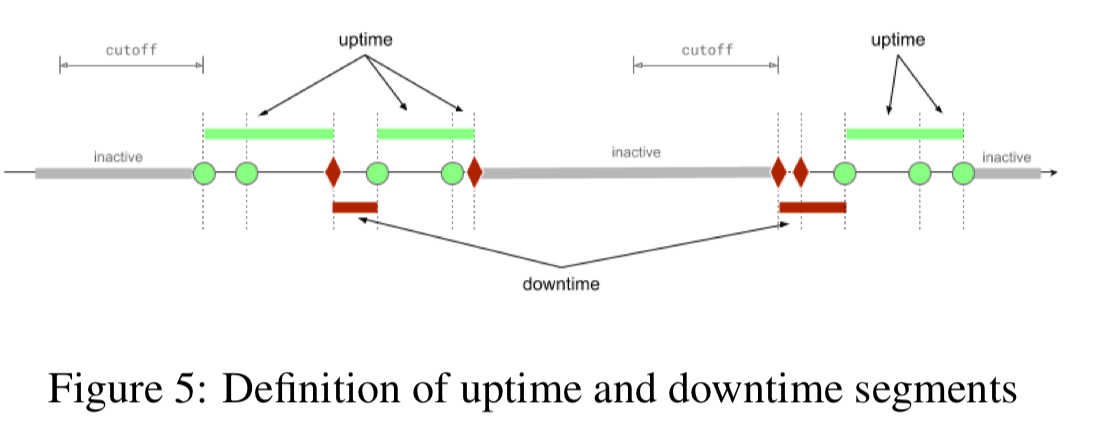
- 下図のようなuptimeとdowntimeを定義し,uptimeの割合を可用性として利用
- 式は $\displaystyle \mathrm{user\ uptime} = \frac{\sum_{u \in users} \mathrm{uptime}(u)}{\sum_{u \in users} \mathrm{uptime}(u) + \mathrm{downtime}(u)}$
- 一定期間アクセスがないところはinactiveとして処理
- 下図のようなuptimeとdowntimeを定義し,uptimeの割合を可用性として利用
Tagged: #monitoring